May 5, 20255 min read
Learned Diffusion Priors to Optimize Gaussian Splatting
Novel view synthesis in 3D reconstruction with sparse-view inputs, using learned priors from image generation models.

What if we teach a model how the world is "supposed" to look like, to help it build better 3D reconstructions.
TLDR: This blog post details a research project I worked on the past couple weeks exploring various techniques to improve sparse view 3D Gaussian Splatting for novel view tasks.
You can read the full research paper here.
You can find the research repository here.
3D Gaussian Splatting is one of the most efficient ways to convert 2D videos into 3D representations. It works by optimizing millions of anisotropic Gaussians—tiny ellipsoids in 3D space—so that, when projected into a camera’s viewpoint, they reproduce the appearance of the object from that perspective. With dense multi-view coverage, the process is constrained enough to produce sharp, photorealistic results. But with sparse inputs (only 4–6 views) the optimization is underdetermined. Two failure modes dominate: covariances “inflate” along unconstrained directions so splats stretch like taffy, and depth ambiguity lets Gaussians slide along viewing rays, which bends geometry and smears texture from novel angles. It’s not that the model “forgets” 3D; it just has too many valid explanations for the pixels it saw.

Common sparse-view artifacts in 3DGS: elongated splats, misplaced geometry, and severe blur.
Approach
Instead of trying to prevent those artifacts during the initial optimization, I leaned into a simple loop: render, repair, retrain. Let 3DGS run on sparse data, take its flawed novel views, correct them with an image restoration model, and then fine-tune the 3D representation on those corrected views so the scene itself improves.
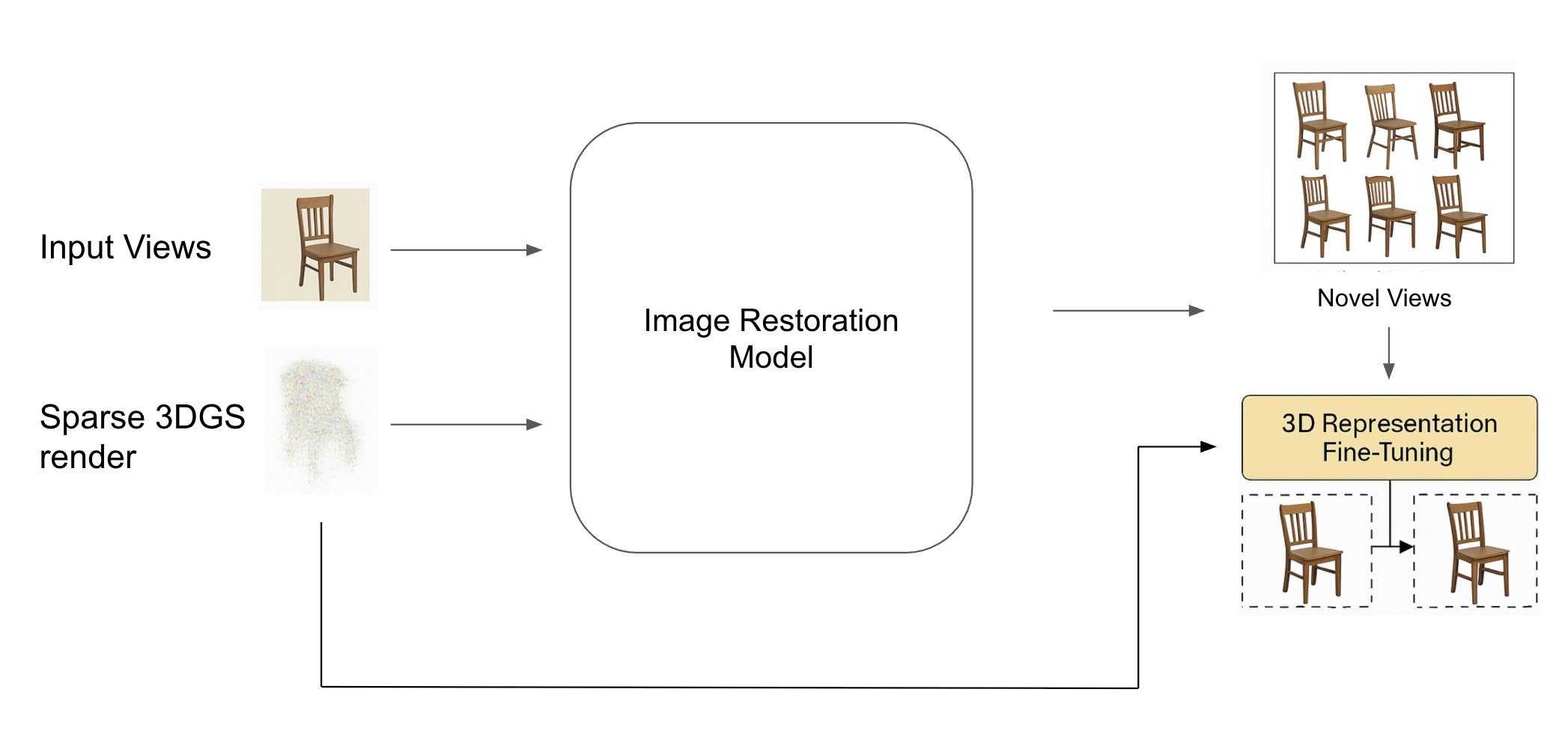
Render–repair–retrain: sparse 3DGS → restoration model → corrected novel views → 3D fine-tuning.
The decision to decouple reconstruction from correction came from an observation in my experiments: under sparse coverage, 3DGS errors are systematic but locally correctable. Covariance inflation and depth ambiguity—well-documented failure modes in sparse-view Gaussian optimization—create artifacts that are easier to spot and fix in 2D projections than in the raw 3D parameter space. Prior works like DiffusioNeRF and 3DGS-Enhancer have shown that injecting view-consistent 2D priors can regularize a 3D model without changing its core optimizer. My pipeline pushes that idea further: I explicitly treat the 3D model’s output as training data for a 2D restorer, then feed the improved views back into the 3D optimizer. This not only leverages pixel-perfect supervision but also avoids the instability that can come from applying strong generative priors directly inside the 3D optimization loop.
Dataset
I built a paired dataset: for each camera pose, one image from sparse-view 3DGS (artifact) and one “clean” rendering from a dense-capture reference. That gave the restorer exact before/after targets at identical viewpoints. I trained several different sparse-view 3DGS for each 3d rendering, building a dataset of around 10,000 image pairs.

Paired dataset samples: artifact, clean reference, and absolute error map (hotter = larger error).
The first approach I tried was a diffusion-based method using FLUX 1-dev with ControlNets for edges and monocular depth. The appeal was obvious: a strong generative prior that can hallucinate plausible high-frequency detail, steered by structure cues so it doesn’t wander. It did produce sharp textures and sometimes dramatic visual cleanups, but it also tended to drift in color temperature or illumination frame to frame. Those photometric inconsistencies turned into multi-view disagreements during 3DGS fine-tuning and reintroduced artifacts downstream—the classic “looks good per-frame, breaks in aggregate” failure mode.

ControlNet + FLUX 1-dev: sharper textures but frame-to-frame color/lighting drift; see error map.
The second approach was NAFNet, a lightweight, activation-free CNN built for restoration. No generative prior, no extra conditioning—just straightforward, local edits learned from the paired data. That simplicity was a feature: it clipped elongated splats, re-sharpened edges in blurry zones, and crucially kept geometry and color consistent across the entire sequence. Sometimes the fixed regions were a touch smoother than ideal, but for 3DGS retraining, correctness beats invented detail. When I injected NAFNet-restored frames into a short fine-tune, PSNR/SSIM rose across near, mid, and far view bands, and the Gaussians contracted instead of stretching, yielding cleaner geometry from unseen angles.

NAFNet: geometry-respecting cleanup and tight error residuals concentrated on thin outlines.
The third approach was mask-aware inpainting with FLUX-Fill-dev. I detected artifact regions via a Laplacian-of-Gaussian mask and asked the inpainting model to modify only those pixels. This was great for small blemishes—it left the rest of the image pristine and convincingly patched isolated splats. But when the corrupted area was large, the model had too much creative freedom and occasionally hallucinated big structural elements that weren’t in the scene. Those hallucinations broke multi-view consistency and limited the gains after retraining.

FLUX-Fill inpainting: effective on small masks; large regions can introduce non-existent structure.
Once the restored views—especially the NAFNet ones—were fed back into 3DGS for a short fine-tune, the improvements persisted in the 3D itself. Novel views stayed sharper and more stable as the camera moved away from the training poses, and the error maps thinned out to narrow outlines rather than broad swaths. The simple loop ended up doing most of the heavy lifting: render the bad views, repair them with a model that values consistency over flash, and retrain the scene so the corrections become part of its internal geometry and appearance.
The bigger lesson for me is that in sparse-data regimes, a reliable post-process can matter more than a clever core model tweak. It’s okay to let one part of the system make mistakes if you have another part that reliably fixes them—and then you close the loop so the whole system learns the correction. It’s a humble way to get to “how the world is supposed to look,” one repaired view at a time.